
Entreprises concernées par cet article
Autres articles de CALASYS
CALASYS pour une gestion optimisée des réseaux.">
Industrialisation des données : enjeux et stratégies pour la digitalisation des réseaux
Le 24/02/2026
- Par :
CALASYS
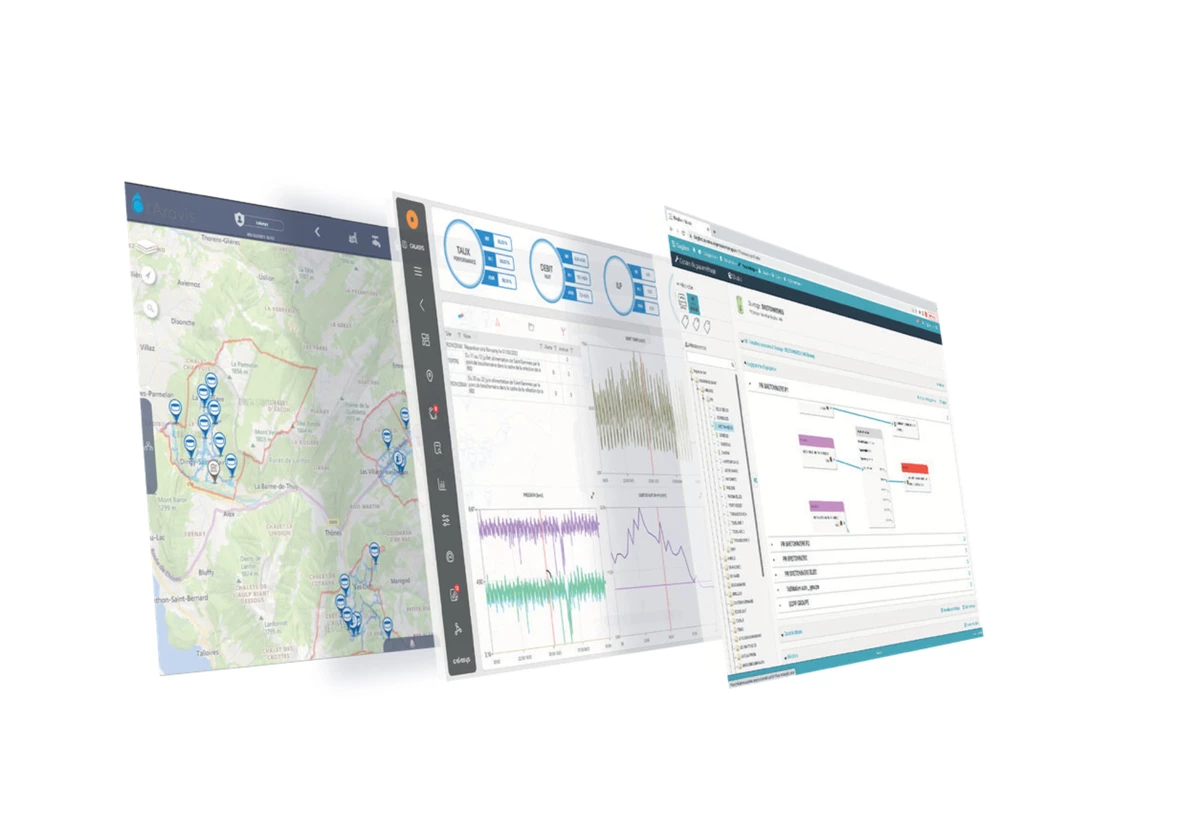
Découvrez comment l'industrialisation des données transforme la digitalisation des réseaux. Analyse des défis opérationnels, des normes en vigueur, des méthodes innovantes et des solutions proposées par CALASYS pour une gestion optimisée des réseaux.